Contente
- Definição - O que significa Apache Kudu?
- Uma introdução ao Microsoft Azure e Microsoft Cloud | Neste guia, você aprenderá sobre o que é a computação em nuvem e como o Microsoft Azure pode ajudá-lo a migrar e administrar seus negócios a partir da nuvem.
- Techopedia explica Apache Kudu
Definição - O que significa Apache Kudu?
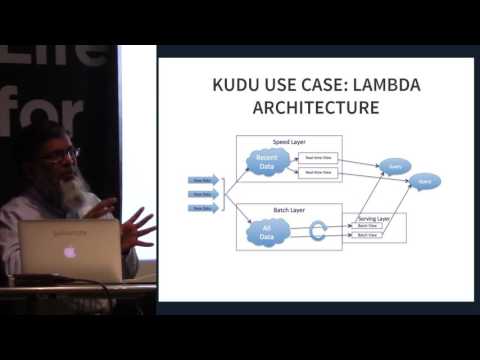
O Apache Kudu é um membro do ecossistema Apache Hadoop de código aberto. É um mecanismo de armazenamento de código aberto destinado a dados estruturados que suporta acesso aleatório de baixa latência junto com padrões de acesso analítico eficientes. Ele foi projetado e implementado para preencher a lacuna entre o sistema de arquivos distribuídos (HDFS) Hadoop amplamente utilizado e o banco de dados HBase NoSQL. Embora esses sistemas ainda possam ser vantajosos, o Apache Kudu pode atender a muitas cargas de trabalho comuns, pois pode simplificar drasticamente sua arquitetura.
Uma introdução ao Microsoft Azure e Microsoft Cloud | Neste guia, você aprenderá sobre o que é a computação em nuvem e como o Microsoft Azure pode ajudá-lo a migrar e administrar seus negócios a partir da nuvem.
Techopedia explica Apache Kudu
O Apache Kudu foi desenvolvido principalmente como um projeto na Cloudera. A maioria das contribuições até o momento foi de desenvolvedores empregados pela Cloudera. Durante seu lançamento, apenas binários de conveniência foram incluídos nos repositórios da Cloudera, no entanto, adotou o processo de liberação da fonte Apache Software Foundation (ASF) ao ingressar na incubadora. Ele foi projetado especificamente para casos de uso que exigem análises rápidas em dados rápidos. Foi projetado para aproveitar o hardware de próxima geração e o processamento na memória. Reduz significativamente a latência da consulta para o Apache Impala e o Apache Spark. Ele distribui os dados por meio do mecanismo de armazenamento colunar ou por particionamento horizontal e, em seguida, replica cada partição usando o consenso do Raft, fornecendo baixo tempo médio de recuperação e latências de cauda baixas.
Embora o Kudu seja um produto projetado dentro do ecossistema do Apache Hadoop, ele também suporta a integração com outros projetos de análise de dados, dentro e fora do ASF.
O Apache Kudu prova ser eficiente, pois pode processar cargas de trabalho analíticas em tempo real em uma única camada de armazenamento, dando aos arquitetos flexibilidade para lidar com uma variedade maior de casos de uso sem soluções exóticas.